Compilers and Static Analyzers
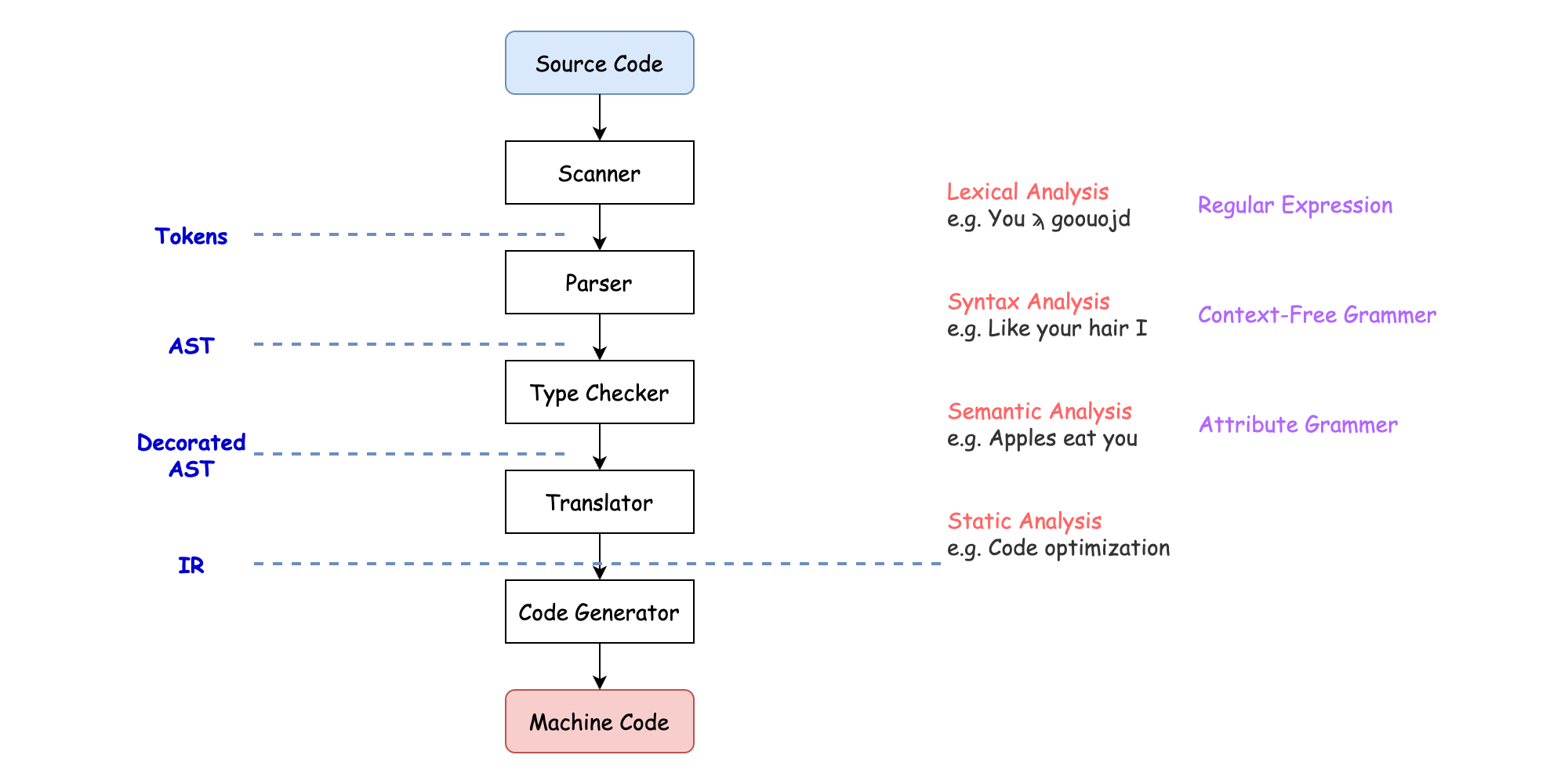
编译通常包括词法分析、语法分析、语义分析等过程,最终生成机器码。源代码向机器码转化的过程大致如下:
- 在词法分析阶段,编译器将源程序分成一个一个的Token,划分出是关键字还是标识符还是运算符等,利用Regular Expression(正则表达式)来实现;
- 在语法分析阶段,将一个个的Token组成句子,利用Context-Free Grammar(上下文无关文法,CFG)来实现,构造出AST;
- 在语义分析阶段,会进行类型检测等,构造出修饰后的AST;
- 在翻译阶段,常将Decorated AST翻译为生成三地址码这样的中间表示形式(Intermediate Representation,IR),并基于IR进行静态分析(例如代码优化等);
- 在机器码生成阶段,将IR转化成物理CPU能够直接执行的比特序列,即机器代码。
AST vs IR
在编译过程中可以看到有两类中间结果:AST和IR,那么为什么静态分析基于IR进行实现而不是选择AST呢?
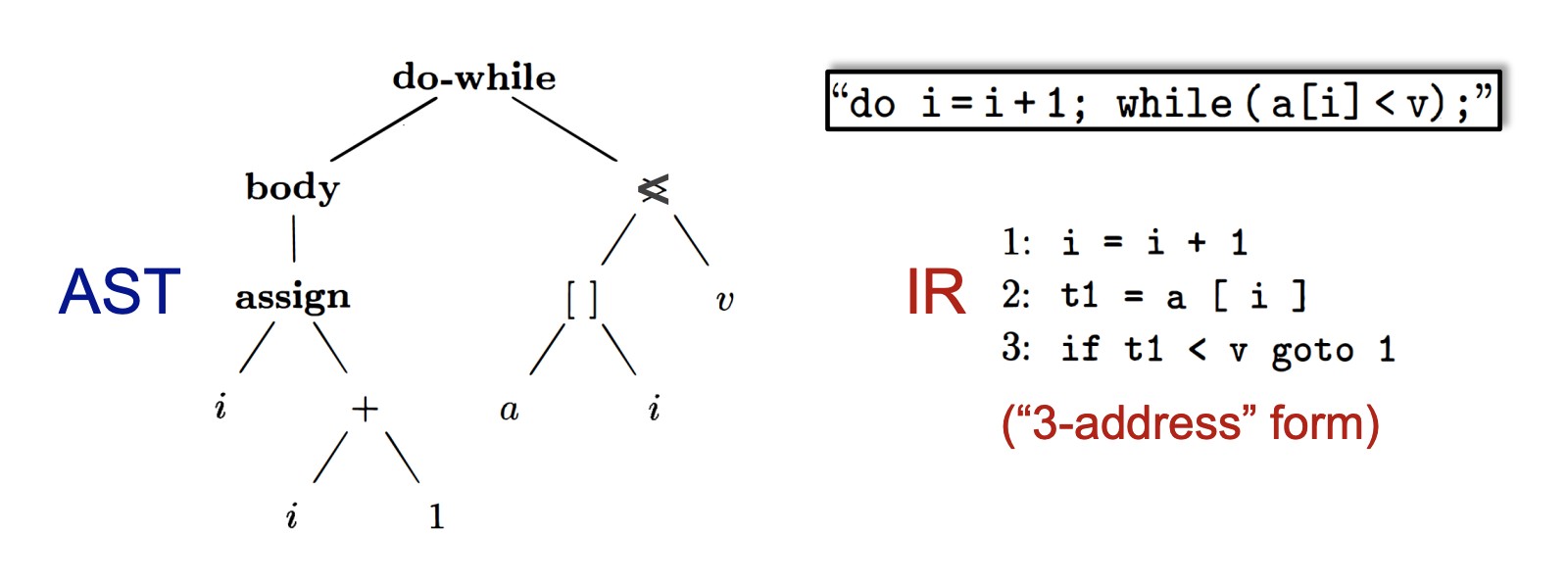
在上图例子中可以看出IR相较于AST有如下优点,因此IR更适合作为静态分析的基础。
- AST是high-level且接近语法结构的,而IR是low-level且接近机器代码的。
- AST是依赖于语言的,IR通常是独立于语言的,三地址码会被分析器重点关注,因为可以将各种前端语言统一翻译成同一种IR再加以优化。
- AST适合快速类型检查,IR的结构更加紧凑和统一,在AST中包含了很多非终结符所占用的结点(body,assign等),而IR中不会需要到这些信息。
- AST缺少控制流信息,IR包含了控制流信息,AST中只是有结点表明了这是一个do-while结构,但是无法看出控制流信息,而IR中的goto等信息可以轻易看出控制流。
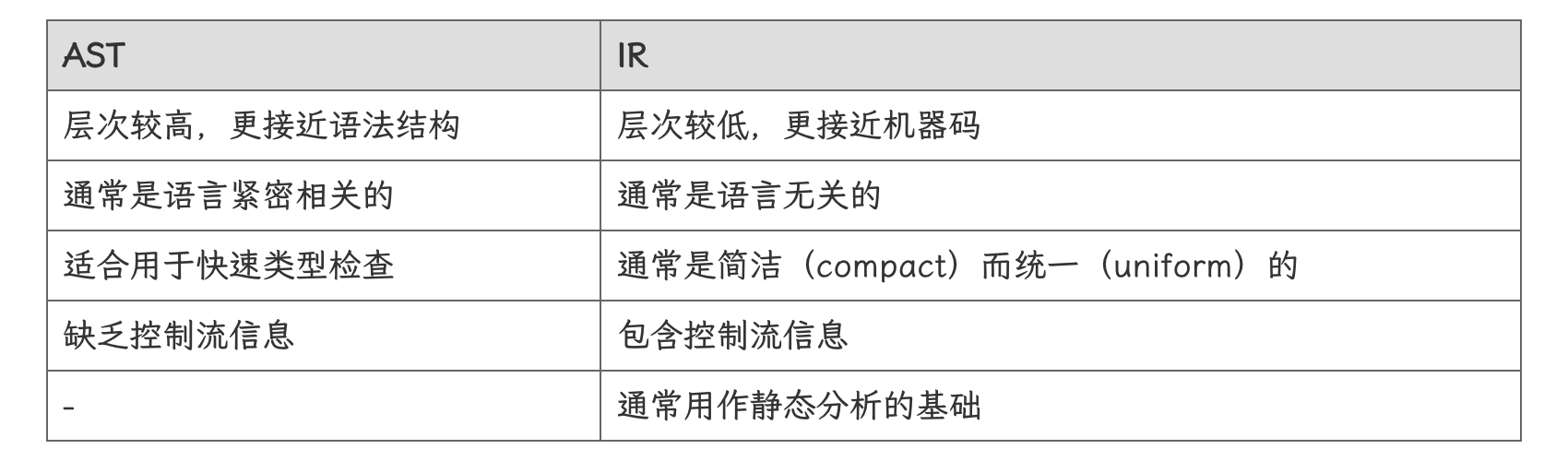
总结而言,AST与IR各有以下特点。
Three-Address Code
IR常用的表示形式是三地址码(3-Address Code,简称3AC),其通常没有统一的格式。
三地址码要求在一个指令的右边至多只有一个操作符,例如,对于a + b + 3这样的语句,3AC需要引入临时变量来将其转换为指令t1 = a + b和指令t2 = t1 + 3。
所谓三地址码,指的是每个3AC指令可以至多包含三种地址:变量名(例如a,b等)、常量(例如3,-100等)以及编译器生成的临时变量(例如t1,t2等)。
下面是一些常见的3AC形式:

3AC在真实静态分析中的应用,https://github.com/soot-oss/soot。Soot是一种到Java静态分析框架,它的IR叫做Jimple,一种有类型的三地址码(Typed 3AC)。
Soot下载地址可以参考:https://repo.maven.apache.org/maven2/org/soot-oss/soot/,以下是几个Jimple的示例。
- Do-While Loop
1 | public class DoWhileLoop3AC { |
1 | # 预先生成class文件,然后再执行Soot |
1 | public class DoWhileLoop3AC extends java.lang.Object |
- Method Call
- invokespecial:call constructor,call superclass methods,call private methods
- invokevirtual:instance methods call(virtual dispatch,派生)
- invokeInterface:cannot optimization,checking interface implementation
- invokestatic:call static methods
1 | public class MethodCall3AC { |
1 | # 预先生成class文件,然后再执行Soot |
1 | public class MethodCall3AC extends java.lang.Object |
- Class
1 | public class Class3AC { |
1 | # 预先生成class文件,然后再执行Soot |
1 | public class Class3AC extends java.lang.Object |
Static Single Assignment
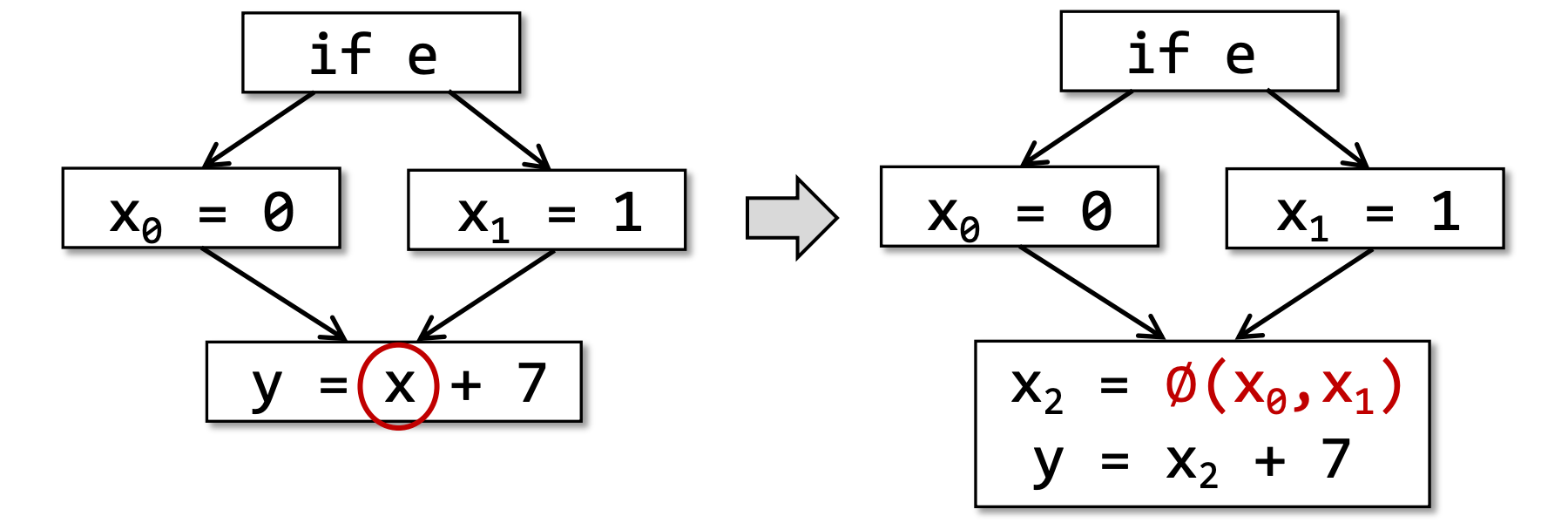
Static Single Assignment(静态单一赋值,SSA),在3AC的基础上,SSA指的是所有赋值操作的被赋值变量都需要有一个单独的名字。每个定义都会有一个新名字,这个新名字可以应用在后续的分析中,每个变量都有一个定义。
- Give each definition a fresh name
- Propagate fresh name to subsequent uses
- Every variable has exactly one definition
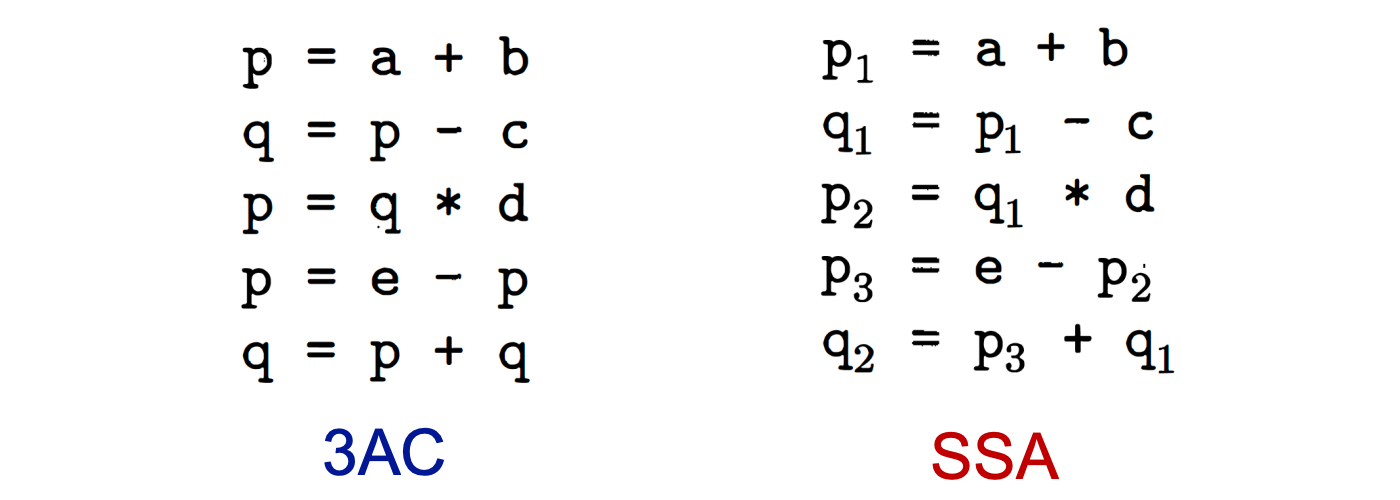
但是有些时候,某些变量可能受到条件分支影响,处于控制流汇聚的位置(control flow merges),此时就需要使用φ函数来处理,其中,φ(x0,x1)的值由控制流经过的条件分支决定。
SSA的优缺点如下:
- 优点
- 控制流信息可以间接融合到独特变量名中,简化分析过程
- Define-and-Use配对是明确清楚的
- 缺点
- 可能引入过多变量和φ函数
- 可能造成机器码生成效率低下
Basic Blocks
Basic Block指的是一个连续、最长的3AC序列,该序列具有以下特性:
- 控制流只能从该序列的起始指令进入
- 控制流只能从该序列的最后一条指令退出
那么针对一段3AC,如何将其划分成不同的Basic Block呢?根据Basic Block的定义,不难构造如下的算法来划分Basic Block。
确定3AC序列中的leaders,leaders包括具有以下特性的指令:
- 3AC序列中的第一条指令
- 所有有条件跳转或无条件跳转的所有目标指令
- 所有有条件跳转或无条件跳转后面的一条指令
构建3AC序列的BB:
- BB包含leader指令及其后面紧邻的所有非leader指令

下图是一个3AC划分为不同的Basic Block的结果。


Control Flow Graphs
除了Basic Block,Control Flow Graphs中还会有块到块的边。在划分好Basic Block的基础上,可以构建CFG。CFG具有如下特性:
- The nodes of CFG are basic blocks
- There is an edge from block A to block B if and only if
- There is a conditional or unconditional jump from the end of A to the beginning of B(A的末尾有一条指向了B开头的有条件或无条件跳转指令)
- B immediately follows A in the original order of instructions and A does not end in an unconditional jump(B是A后面的紧邻块且A最后一条指令不是无条件跳转)

- It is normal to replace the jumps to instruction labels by jumps to basic blocks(将原来3AC序列中的所有“跳转到某指令标签处”改为“跳转到某基本块处”)
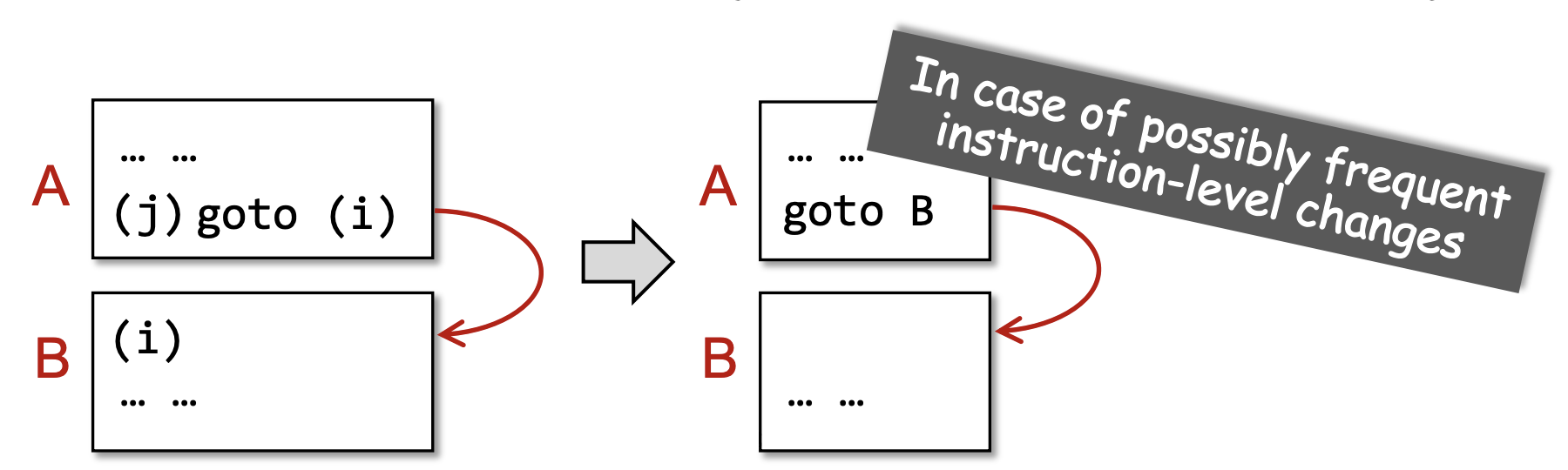
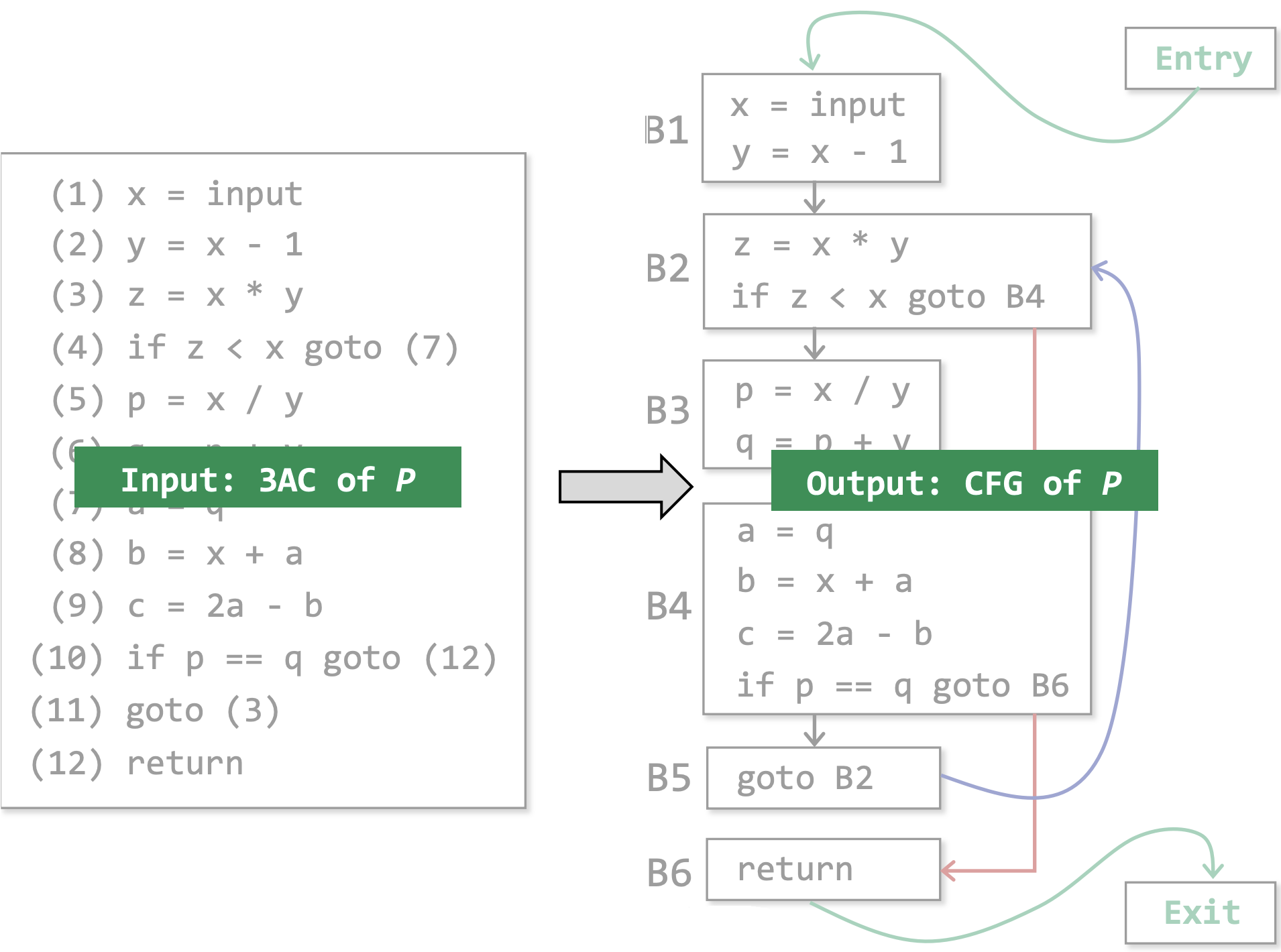
根据上文CFG的特性,下图是在划分好Basic Block的基础上构建的CFG。
- 在A->B中,A是B的前驱(predecessor),B是A的后继(successor)
- 除了构建好的Basic Block,还会额外添加两个结点,入口(Entry)和出口(Exit)
- 这两个结点不对应任何IR
- 入口有一条边指向IR中的第一条指令当某个Basic Block的最后一条指令会让程序离开这段IR,则该Basic Block会有一条边指向出口