1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
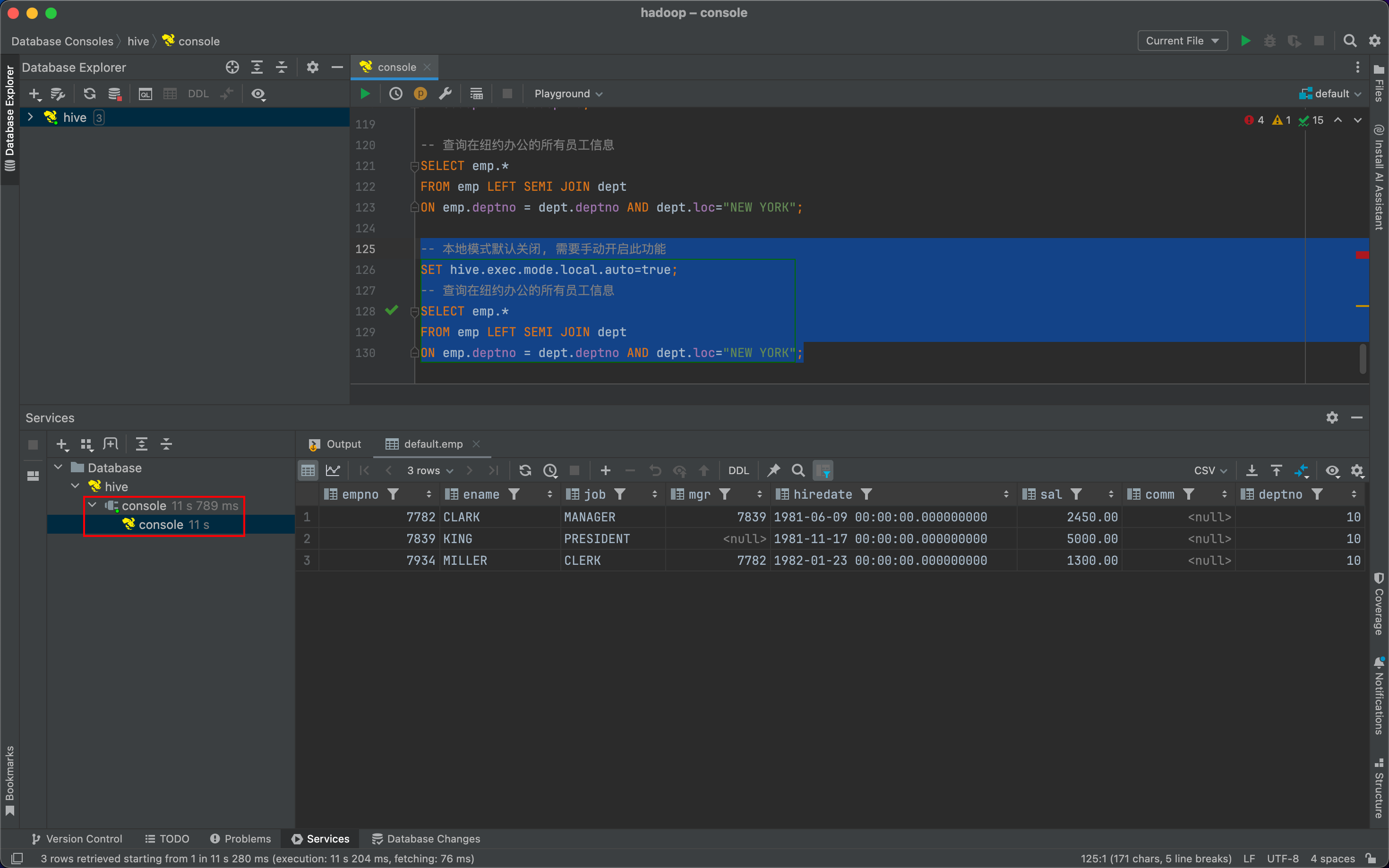
| -- 查询表中全部数据
SELECT * FROM emp;
-- 查询20号部门中员工编号大于7566的员工信息
SELECT * FROM emp WHERE empno > 7566 AND deptno = 20;
-- 查询所有工作类型, Hive支持使用DISTINCT关键字去重
SELECT DISTINCT job FROM emp;
-- 查询分区表中部门编号在[20,40]之间的员工
SELECT emp_ptn.* FROM emp_ptn
WHERE emp_ptn.deptno >= 20 AND emp_ptn.deptno <= 40;
-- 查询薪资最高的3名员工
SELECT * FROM emp ORDER BY sal DESC LIMIT 3;
-- 分组聚合查询, 查询各个部门薪酬综合
-- hive.map.aggr控制程序如何进行聚合, 默认值为false, 如果设置为true, Hive会在map阶段就执行一次聚合, 可以提高聚合效率但需要消耗更多内存
set hive.map.aggr=true;
SELECT deptno,SUM(sal) FROM emp GROUP BY deptno;
-- 使用ORDER BY时会有一个Reducer对全部查询结果进行排序, 可以保证数据的全局有序性
-- 使用SORT BY时只会在每个Reducer中进行排序, 这可以保证每个Reducer的输出数据是有序的, 但不能保证全局有序
-- 由于ORDER BY的时间可能很长, 如果设置了严格模式(hive.mapred.mode = strict), 则其后面必须再跟一个limit子句
-- 查询员工工资, 结果按照部门升序, 按照工资降序排列
SELECT empno, deptno, sal FROM emp ORDER BY deptno ASC, sal DESC;
-- 使用HAVING对分组数据进行过滤, 查询工资总和大于9000的所有部门
SELECT deptno,SUM(sal) FROM emp GROUP BY deptno HAVING SUM(sal)>9000;
-- 默认情况下, MapReduce程序会对Map输出结果的Key值进行散列并均匀分发到所有Reducer上
-- 如果想要把具有相同Key值的数据分发到同一个Reducer进行处理, 这就需要使用DISTRIBUTE BY
-- 需要注意的是, DISTRIBUTE BY虽然能保证具有相同Key值的数据分发到同一个Reducer, 但是不能保证数据在Reducer上是有序的, 可以结合SORT BY使用来让Reducer上的数据有序
-- 将数据按照部门分发到对应的Reducer上处理
SELECT empno, deptno, sal FROM emp DISTRIBUTE BY deptno SORT BY deptno ASC;
-- 如果SORT BY和DISTRIBUTE BY指定的是相同字段, 且SORT BY排序规则是ASC, 此时可以使用CLUSTER BY进行替换, 同时CLUSTER BY可以保证数据在全局是有序的
SELECT empno, deptno, sal FROM emp CLUSTER BY deptno;
|