BPF BPF(Berkeley Packet Filter,伯克利数据包过滤)于1992年在论文“The BSD Packet Filter: A New Architecture for User-level Packet Capture”中被提出。当时设计的BPF具有以下两个特性:
内核态引入一个新的虚拟机,所有的指令都在内核虚拟机中运行;
用户态使用BPF字节码来定义过滤表达式,然后传递给内核,由内核虚拟机解释执行。
BPF技术可在无需编译内核或加载内核模块的情况下,安全地高效地附加到内核的各种事件上,对内核事件进行监控、跟踪和可观测性,避免了向用户态复制每个数据,极大提升了包过滤性能。
在Linux 2.1.75中,首次引入了BPF技术;在Linux 3.0中,增加了BPF即时编译器,它替换掉了原本性能更差的解释器,优化了BPF指令运行的效率,但BPF只是一种数据包过滤技术。
eBPF 2014年,Alexei Starovoitov将BPF扩展为一个通用的虚拟机,即eBPF(Extended Berkeley Packet Filter,扩展的伯克利包过滤器)。eBPF不仅扩展了寄存器的数量,引入了全新的BPF映射存储,同时还在Linux 4.x中将原本单一的数据包过滤事件逐步扩展到了内核态函数、用户态函数、跟踪点、性能事件以及安全控制等。
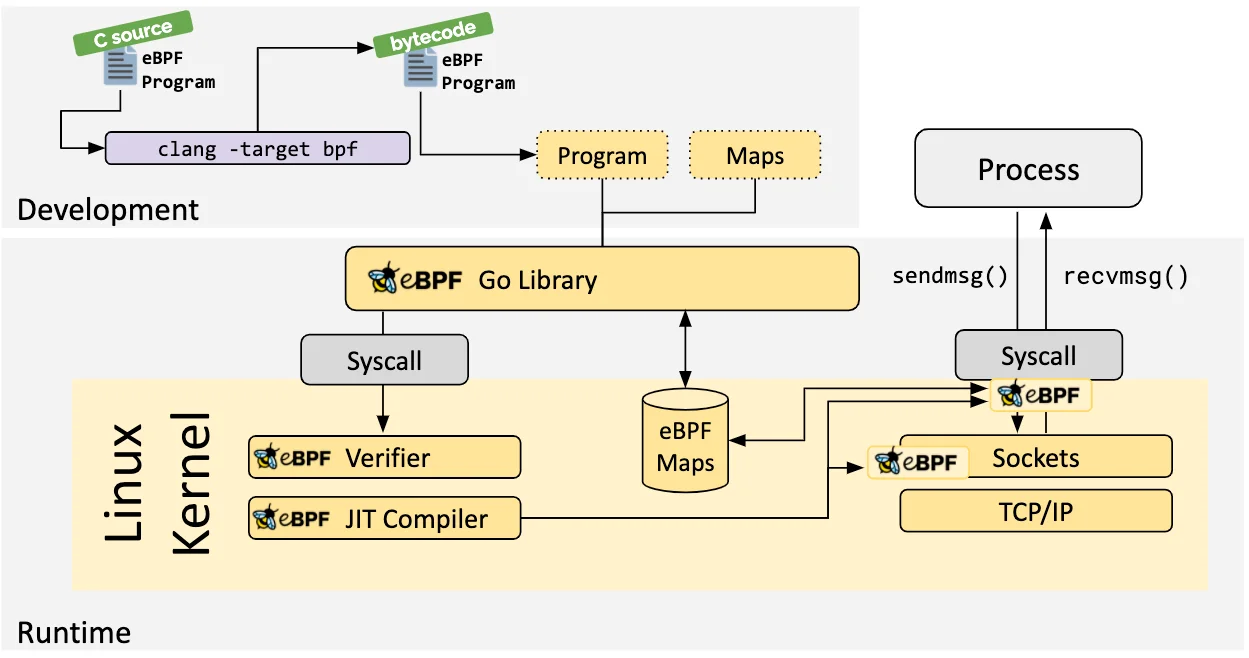
eBPF的诞生是BPF技术的一个转折点,使得BPF不在局限于网络栈,而是成为内核的一个顶级子系统。它与传统方法需要修改内核源代码或加载新模块不同,eBPF使得动态定制和优化网络行为成为可能,且不会中断系统操作。eBPF的整个发展流程如下图所示,目前eBPF广泛用于网络、安全、可观测等领域。
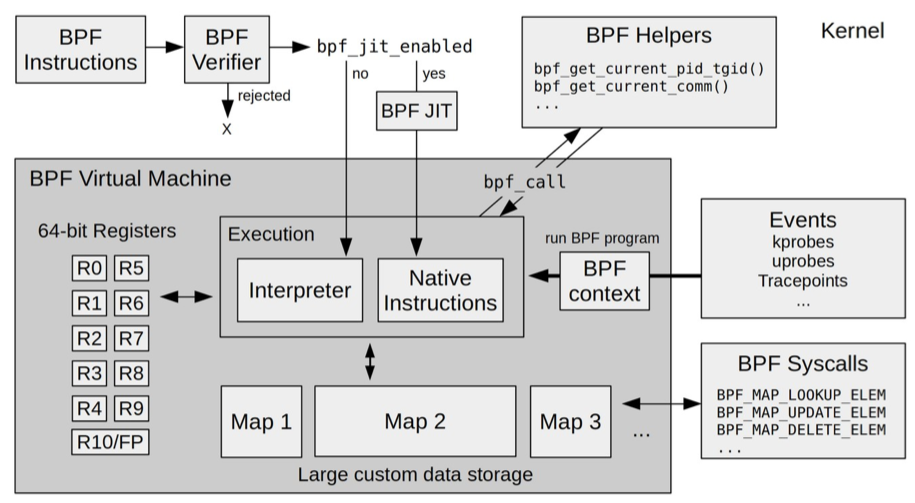
内核原理 eBPF是一个运行在内核中的虚拟机,与系统虚拟化(例如kvm)中的虚拟机存在本质不同。系统虚拟化基于x86或arm64等通用指令集,这些指令集足以完成完整计算机的所有功能。而为了确保在内核中安全地执行,eBPF只提供了非常有限的指令集。这些指令集可用于完成一部分内核的功能,但却远不足以模拟完整的计算机。如下图所示,eBPF在内核中的运行时主要由5个模块组成:
eBPF辅助函数。它提供了一系列用于eBPF程序与内核其他模块进行交互的函数,这些函数并不是任意一个eBPF程序都可以调用的,具体可用的函数集由BPF程序类型决定。
eBPF验证器。它用于确保eBPF程序的安全,验证器会将待执行的指令创建为一个有向无环图(DAG),确保程序中不包含不可达指令;接着再模拟指令的执行过程,确保不会执行无效指令。
存储模块。该模块是由11个64位寄存器、一个程序计数器和一个512字节的栈组成的存储模块。这个模块用于控制eBPF程序的执行。其中,R0寄存器用于存储函数调用和eBPF程序的返回值,这意味着函数调用最多只能有一个返回值;R1-R5寄存器用于函数调用的参数,因此函数调用的参数最多不能超过5个;而R10则是一个只读寄存器,用于从栈中读取数据。
即时编译器。它将eBPF字节码编译成本地机器指令,以便更高效地在内核中执行。
BPF映射。它用于提供大块的存储,这些存储可被用户空间程序用来进行访问,进而控制eBPF程序的运行状态。
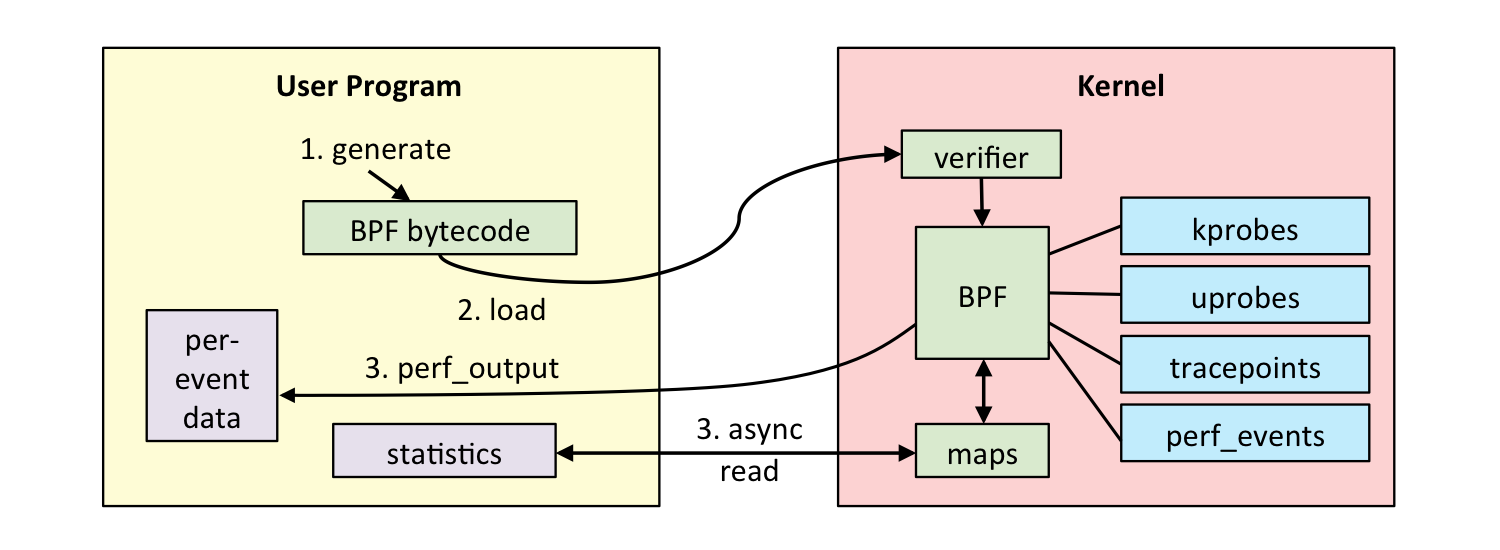
内核交互 eBPF程序是事件驱动的,当内核或应用程序通过某个钩子点时运行。预定义的钩子包括系统调用、函数入口/退出、内核跟踪点、网络事件等。如果预定义的钩子不能满足特定需求,则可以创建内核探针(kprobe)或用户探针(uprobe),以便在内核用户或应用程序的几乎任何位置附加eBPF程序。
验证:验证步骤用于保证eBPF程序可以安全运行。它可以验证程序是否满足几个条件:
加载eBPF程序的进程必须有必需的能力(特权),除非启用非特权eBPF,否则只有特权进程可以加载eBPF程序;
eBPF程序不会崩溃或者对系统造成损害;
eBPF程序一定会运行至结束(即程序不会处于循环状态中,否则会阻碍后续的处理)。
JIT编译:JIT(Just-in-Time)编译步骤将程序的通用字节码高效转换为机器的特定指令集,从而优化程序的执行。这使得eBPF程序可以像本地编译的内核代码或作为内核模块加载的代码一样地运行。
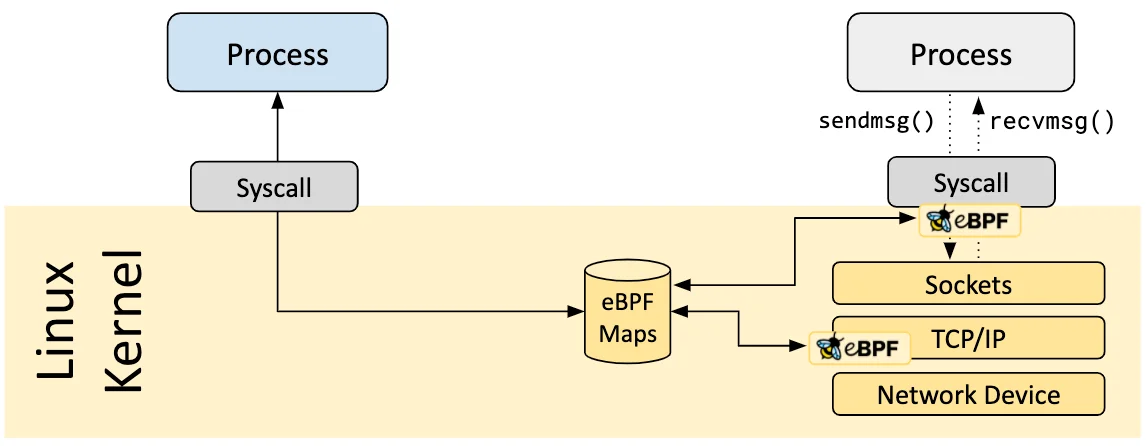
eBPF程序的其中一个重要方面是共享和存储所收集的信息和状态的能力。为此,eBPF程序可以利用eBPF Maps的概念来存储和检索各种数据结构中的数据。如下图所示,eBPF Maps既可以从eBPF程序访问,也可以通过系统调用从用户空间中的应用程序访问。
这其中,最关键的是设置映射的类型。内核头文件bpf.h 中的bpf_map_type定义了所有支持的映射类型,也可以使用bpftool命令bpftool feature probe | grep map_type来查询当前系统支持哪些映射类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 enum bpf_map_type { BPF_MAP_TYPE_UNSPEC, BPF_MAP_TYPE_HASH, BPF_MAP_TYPE_ARRAY, BPF_MAP_TYPE_PROG_ARRAY, BPF_MAP_TYPE_PERF_EVENT_ARRAY, BPF_MAP_TYPE_PERCPU_HASH, BPF_MAP_TYPE_PERCPU_ARRAY, BPF_MAP_TYPE_STACK_TRACE, BPF_MAP_TYPE_CGROUP_ARRAY, BPF_MAP_TYPE_LRU_HASH, BPF_MAP_TYPE_LRU_PERCPU_HASH, BPF_MAP_TYPE_LPM_TRIE, BPF_MAP_TYPE_ARRAY_OF_MAPS, BPF_MAP_TYPE_HASH_OF_MAPS, BPF_MAP_TYPE_DEVMAP, BPF_MAP_TYPE_SOCKMAP, BPF_MAP_TYPE_CPUMAP, BPF_MAP_TYPE_XSKMAP, BPF_MAP_TYPE_SOCKHASH, BPF_MAP_TYPE_CGROUP_STORAGE, BPF_MAP_TYPE_REUSEPORT_SOCKARRAY, BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE, BPF_MAP_TYPE_QUEUE, BPF_MAP_TYPE_STACK, BPF_MAP_TYPE_SK_STORAGE, BPF_MAP_TYPE_DEVMAP_HASH, BPF_MAP_TYPE_STRUCT_OPS, BPF_MAP_TYPE_RINGBUF, BPF_MAP_TYPE_INODE_STORAGE, BPF_MAP_TYPE_TASK_STORAGE, BPF_MAP_TYPE_BLOOM_FILTER, };
如下图所示,一个完整的eBPF程序通常包含用户态(*_kern.c)和内核态(*_user.c)两部分。其中,用户态负责eBPF程序的加载、事件绑定以及eBPF程序运行结果的汇总输出;内核态运行在eBPF虚拟机中,负责定制和控制系统的运行状态。
内核空间代码定义逻辑
功能 说明
定义事件处理逻辑
编写当某个内核事件触发时要执行的代码(如系统调用被调用、网络包到达、函数进入/退出等)
数据收集与过滤
在内核态直接捕获数据,进行初步过滤和聚合,减少用户态开销
Map操作
将处理结果写入BPF Map(内核与用户空间共享的键值存储)
触发通知
通过bpf_ringbuf_submit()或perf_event向用户空间发送事件
1 2 3 4 5 6 7 8 SEC("tracepoint/syscalls/sys_enter_openat" ) int trace_openat (struct trace_event_raw_sys_enter *ctx) { bpf_printk("PID %d opening file" , bpf_get_current_pid_tgid() >> 32 ); return 0 ; }
用户空间代码负责加载和与内核交互
功能 说明
加载eBPF程序
将编译好的*_kern.o字节码加载进内核,经过验证器检查
附着到钩子点
把程序挂到具体的事件源(如tracepoint、kprobe、XDP等)
管理BPF Map
创建、读取、更新Map,与内核程序交换数据
处理数据输出
从Map或Ring Buffer读取结果,格式化输出(打印、存文件、发网络等)
生命周期控制
信号处理、优雅退出、资源清理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int main () { struct bpf_object *obj ="program_kern.o" , NULL ); bpf_object_load(obj); struct bpf_program *prog ="trace_openat" ); bpf_program_attach(prog); struct bpf_map *map ="events" ); while (running) { } bpf_object_close(obj); }
虽然eBPF的功能很强大,但是为了保证内核安全,对eBPF的程序也有很多的限制:
eBPF程序必须被验证器校验通过之后才能执行,且不能包含无法到达的指令;
eBPF程序不能随意调用内核函数,只能调用在API中定义的辅助函数;
eBPF程序栈空间最多只有512字节,可以通过映射保存;
在内核5.2之前,eBPF字节码最多只支持4096条指令,而5.2内核提升至100万条;
由于内核的快速变化,在不同版本内核中运行时,需要访问内核数据结构的eBPF程序就需要修改源代码重新编译。
开发工具链 在实际开发中,eBPF并不是直接使用,而是通过像Cilium、bcc或bpftrace这样的项目间接使用,这些项目提供了eBPF上面的抽象,不需要直接编写定义程序,而是提供了基于意图的来实现的能力,然后用eBPF实现。以下是一些eBPF开发工具:
BCC :一个基于Python的工具链,简化了eBPF程序的编写、编译和加载。它提供了许多预构建的追踪工具,但在依赖和兼容性方面存在一些限制。eBPF Go库 :一个Go库,解耦了获取eBPF字节码的过程与加载和管理eBPF程序的过程。libbpf-bootstrap :基于libbpf的现代脚手架,提供了高效的工作流用于编写eBPF程序,提供简单的一次性编译过程以生成可重用的字节码。eunomia-bpf :一个用于编写仅包含内核空间代码的eBPF程序的工具链,它通过动态加载eBPF程序简化了eBPF程序的开发。Aya :一个纯Rust实现的eBPF开发框架,提供了完全基于Rust的工具链来同时编写内核空间和用户空间代码。
程序分类 概述 根据内核头文件bpf.h 中bpf_prog_type的定义,Linux内核v5.19已经支持30余种不同类型的eBPF程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 enum bpf_prog_type { BPF_PROG_TYPE_UNSPEC, BPF_PROG_TYPE_SOCKET_FILTER, BPF_PROG_TYPE_KPROBE, BPF_PROG_TYPE_SCHED_CLS, BPF_PROG_TYPE_SCHED_ACT, BPF_PROG_TYPE_TRACEPOINT, BPF_PROG_TYPE_XDP, BPF_PROG_TYPE_PERF_EVENT, BPF_PROG_TYPE_CGROUP_SKB, BPF_PROG_TYPE_CGROUP_SOCK, BPF_PROG_TYPE_LWT_IN, BPF_PROG_TYPE_LWT_OUT, BPF_PROG_TYPE_LWT_XMIT, BPF_PROG_TYPE_SOCK_OPS, BPF_PROG_TYPE_SK_SKB, BPF_PROG_TYPE_CGROUP_DEVICE, BPF_PROG_TYPE_SK_MSG, BPF_PROG_TYPE_RAW_TRACEPOINT, BPF_PROG_TYPE_CGROUP_SOCK_ADDR, BPF_PROG_TYPE_LWT_SEG6LOCAL, BPF_PROG_TYPE_LIRC_MODE2, BPF_PROG_TYPE_SK_REUSEPORT, BPF_PROG_TYPE_FLOW_DISSECTOR, BPF_PROG_TYPE_CGROUP_SYSCTL, BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE, BPF_PROG_TYPE_CGROUP_SOCKOPT, BPF_PROG_TYPE_TRACING, BPF_PROG_TYPE_STRUCT_OPS, BPF_PROG_TYPE_EXT, BPF_PROG_TYPE_LSM, BPF_PROG_TYPE_SK_LOOKUP, BPF_PROG_TYPE_SYSCALL, };
对于具体的内核来说,因为不同内核的版本和编译配置选项不同,通常一个内核并不会支持所有的程序类型。可以通过执行bpftool feature probe | grep program_type来查询当前系统支持的程序类型。以阿里云云服务为例,内核版本5.15.0-106-generic,可以看到当前内核支持kprobe、tracepoint、xdp、perf_event等程序类型,而不支持tracing、ext、lsm等程序类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 eBPF program_type socket_filter is available eBPF program_type kprobe is available eBPF program_type sched_cls is available eBPF program_type sched_act is available eBPF program_type tracepoint is available eBPF program_type xdp is available eBPF program_type perf_event is available eBPF program_type cgroup_skb is available eBPF program_type cgroup_sock is available eBPF program_type lwt_in is available eBPF program_type lwt_out is available eBPF program_type lwt_xmit is available eBPF program_type sock_ops is available eBPF program_type sk_skb is available eBPF program_type cgroup_device is available eBPF program_type sk_msg is available eBPF program_type raw_tracepoint is available eBPF program_type cgroup_sock_addr is available eBPF program_type lwt_seg6local is available eBPF program_type lirc_mode2 is NOT available eBPF program_type sk_reuseport is available eBPF program_type flow_dissector is available eBPF program_type cgroup_sysctl is available eBPF program_type raw_tracepoint_writable is available eBPF program_type cgroup_sockopt is available eBPF program_type tracing is NOT available eBPF program_type struct_ops is available eBPF program_type ext is NOT available eBPF program_type lsm is NOT available eBPF program_type sk_lookup is available
根据具体功能和应用场景的不同,这些程序类型大致可以划分为三类:
跟踪类eBPF程序,即从内核和程序的运行状态中提取跟踪信息,来了解当前系统正在发生什么。
网络类eBPF程序,即对网络数据包进行过滤和处理,来了解和控制网络数据包的收发过程。
其它类eBPF程序,即除跟踪和网络之外的其他类型,包括安全控制、BPF扩展等。
跟踪类eBPF程序 跟踪类eBPF程序主要用于从系统中提取跟踪信息,进而为监控、排错、性能优化等提供数据支撑,包括KPROBE、TRACEPOINT、PERF_EVENT等。下表中包含了常见的跟踪类BPF程序的主要功能以及使用限制。
程序类型 功能描述 功能限制
BPF_PROG_TYPE_KPROBE
用于对特定函数进行动态插桩,根据函数位置的不同,又可以分为内核态kprobe和用户态uprobe
内核函数和用户函数的定义属于不稳定API,在不同内核版本中使用时,可能需要调整eBPF代码实现
BPF_PROG_TYPE_TRACEPOINT
用于内核静态跟踪点,会附加到Linux内核中预定义的跟踪点(可以使用perf list命令来查询所有的跟踪点)
虽然跟踪点可以保持稳定性,但不如KPROBE类型灵活,无法按需增加新的跟踪点
BPF_PROG_TYPE_PERF_EVENT
用于性能事件(perf_events)跟踪,包括内核调用、定时器、硬件等各类性能数据
需配合BPF_MAP_TYPE_PERF_EVENT_ARRAY或BPF_MAP_TYPE_RINGBUF类型的映射使用
BPF_PROG_TYPE_RAW_TRACEPOINT BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE
用于原始跟踪点,直接访问内核传递给跟踪点的原始参数,避免参数解析开销
不处理参数格式化,需要自行解析原始参数
BPF_PROG_TYPE_TRACING
用于开启BTF的跟踪点,支持fentry、fexit、fmod_ret、iter等多种跟踪模式
需要开启BTF调试信息,内核编译时需开启CONFIG_DEBUG_INFO_BTF
网络类eBPF程序 网络类eBPF程序主要用于对网络数据包进行过滤和处理,进而实现网络的观测、过滤、流量控制以及性能优化等各种丰富的功能。根据事件触发位置的不同,网络类eBPF程序又可以分为 XDP(eXpress Data Path,高速数据路径)程序、TC(Traffic Control,流量控制)程序、套接字程序以及cgroup程序。下表中包含了常见的跟踪类BPF程序的主要功能以及使用限制。
XDP程序,类型为BPF_PROG_TYPE_XDP,在网络驱动程序刚刚收到数据包时触发执行。可用来实现高性能的网络处理方案。
TC程序,类型为BPF_PROG_TYPE_SCHED_CLS和BPF_PROG_TYPE_SCHED_ACT,分别作为Linux流量控制的分类器和执行器。
套接字程序,用于过滤、观测或重定向套接字网络包,具体的种类也比较丰富。根据类型的不同,套接字eBPF程序可以挂载到套接字(socket)、控制组(cgroup)以及网络命名空间(netns)等各个位置。
cgroup程序,用于对cgroup内所有进程的网络过滤、套接字选项以及转发等进行动态控制,它最典型的应用场景是对容器中运行的多个进程进行网络控制。
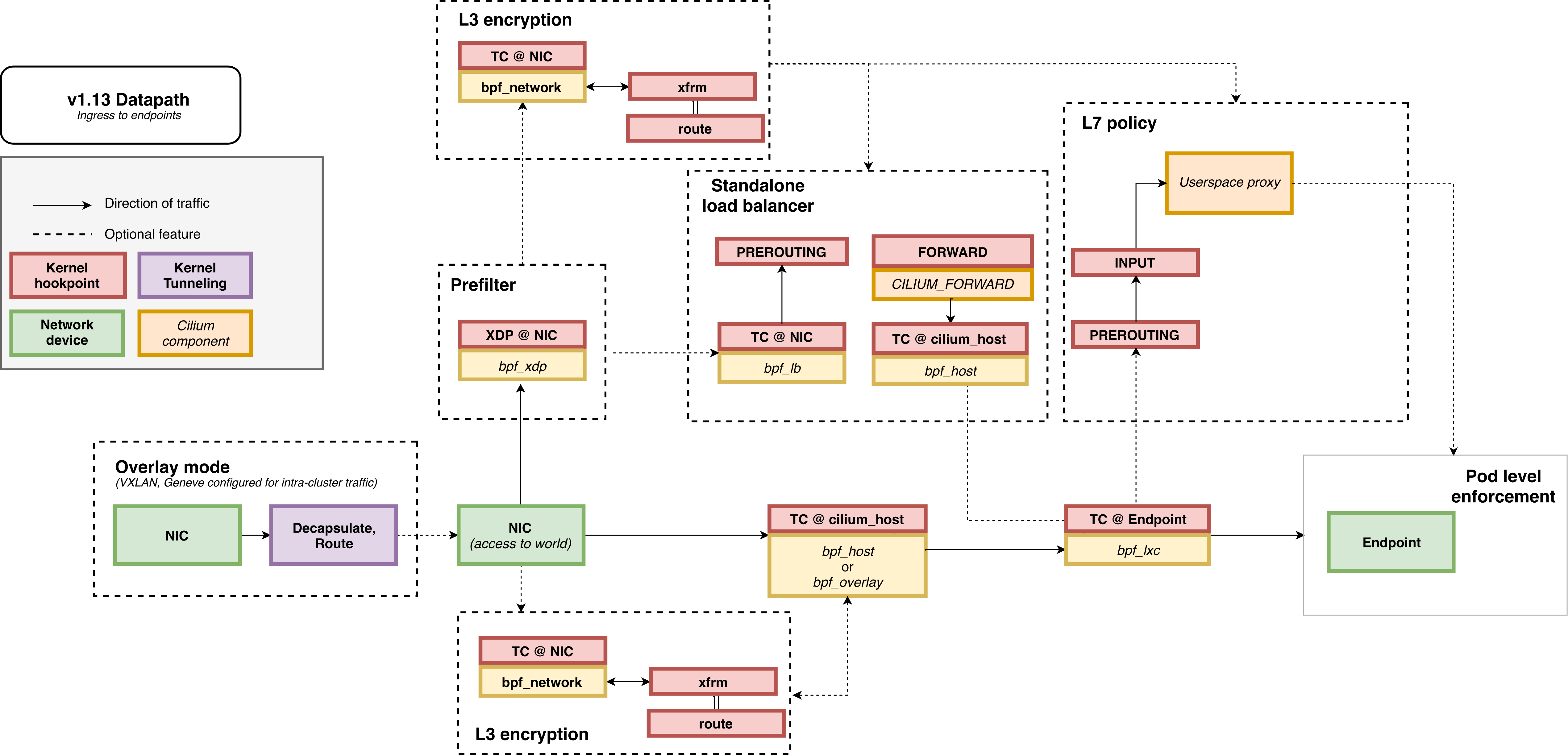
这几类网络eBPF程序是在不同的事件触发时执行的,因此,在实际应用中通常可以把多个类型的eBPF程序结合一起使用,来实现复杂的网络控制功能。例如下图中,Kubernetes的网络方案Cilium就大量使用了XDP、TC和套接字eBPF程序。
下表中包含了常见的网络类BPF程序的主要功能以及使用限制。
程序类型 功能描述 功能限制
BPF_PROG_TYPE_SOCKET_FILTER
用于套接字过滤器,最早的网络类eBPF程序,可过滤套接字接收的数据包
只能用于接收路径,无法修改数据包,功能较为基础,已被更强大的类型替代
BPF_PROG_TYPE_SCHED_CLS
用于流量控制(TC)分类器,在ingress/egress路径对数据包进行分类和过滤
需要配合TC工具使用,仅支持已启用qdisc的网络设备
BPF_PROG_TYPE_SCHED_ACT
用于流量控制(TC)动作,在分类后执行具体的处理动作(如丢弃、重定向、修改)
需要与SCHED_CLS配合使用,依赖TC框架
BPF_PROG_TYPE_XDP
用于XDP,在网络驱动层最早的处理点执行,可实现高性能包处理
运行环境受限(如不支持睡眠、部分内核API不可用),需要网卡驱动支持XDP模式
BPF_PROG_TYPE_SOCK_OPS
用于套接字操作,跟踪TCP连接状态变化(如连接建立、重传、拥塞控制)
主要用于状态跟踪和参数设置,不直接处理数据包内容
BPF_PROG_TYPE_SK_SKB
用于套接字级别的数据包处理,配合sockmap实现套接字之间的数据包转发
需要配合BPF_MAP_TYPE_SOCKMAP使用,配置相对复杂
BPF_PROG_TYPE_SK_MSG
用于套接字消息处理,在sendmsg/recvmsg系统调用层面执行
需要配合BPF_MAP_TYPE_SOCKHASH或SOCKMAP使用
BPF_PROG_TYPE_SK_LOOKUP
用于套接字查找,在数据包到达时自定义选择目标套接字
需要内核5.9+,用于替代或补充内核的套接字查找逻辑
BPF_PROG_TYPE_SK_REUSEPORT
用于SO_REUSEPORT套接字选择,在多个监听套接字之间选择接收连接的目标
仅影响连接分发策略,需要在应用层设置SO_REUSEPORT
BPF_PROG_TYPE_CGROUP_SKB
用于cgroup级别的套接字缓冲区过滤,对cgroup内的网络流量进行过滤
只能过滤,无法修改数据包;需要配合cgroup v2使用
BPF_PROG_TYPE_CGROUP_SOCK
用于cgroup级别的套接字操作,在套接字创建、绑定、监听等时刻执行
仅控制套接字生命周期事件,不处理实际数据包
BPF_PROG_TYPE_CGROUP_SOCK_ADDR
用于cgroup级别的套接字地址绑定,在bind()、connect()等调用时修改地址
仅在连接建立阶段执行,不处理后续数据流
BPF_PROG_TYPE_FLOW_DISSECTOR
用于流解析器,在数据包早期解析协议头,提取流标识信息
解析逻辑受限,不能依赖完整的协议栈状态
其它类eBPF程序 其它类eBPF程序,包括Linux安全模块、轻量级隧道处理,内核结构体修改等。下表中包含了这些不常用BPF程序的主要功能以及应用场景。
程序类型 功能描述 应用场景
BPF_PROG_TYPE_LSM
用于Linux安全模块(Linux Security Module,LSM)访问控制和审计策略
在文件访问、进程创建等关键安全操作点执行,用于安全审计和访问控制;需要内核开启CONFIG_BPF_LSM
BPF_PROG_TYPE_LWT_IN BPF_PROG_TYPE_LWT_OUT BPF_PROG_TYPE_LWT_XMIT 用于轻量级隧道(Lightweight Tunnel)处理,分别在隧道接收、发送、传输阶段执行 用于轻量级隧道(如vxlan、mpls等)的封装或解封装;需要配合iproute2的lwtunnel使用
BPF_PROG_TYPE_LIRC_MODE2 用于红外设备的远程遥控 处理红外信号解码;需要硬件支持LIRC,应用场景较为特定
BPF_PROG_TYPE_STRUCT_OPS 用于修改内核结构体 目前仅支持拥塞控制算法tcp_congestion_ops,可将eBPF程序作为内核回调函数注册,实现自定义TCP拥塞控制算法;需要内核BTF支持
BPF_PROG_TYPE_EXT 用于扩展BPF程序 允许一个程序作为另一个程序的扩展(类似动态链接),用于代码复用和模块化;需要被扩展的程序支持
事件追踪 通过eBPF可以对多种类型的事件进行跟踪,例如内核动/静态跟踪、用户态跟踪、性能分析、网络包过滤、网络流量控制等等。
kprobe/kretprobe kprobe允许在内核函数的入口处插入一个断点。当CPU执行到这个位置时,会触发一个陷入(trap),CPU切换到预先定义的处理函数(probe handler)执行。这个处理函数可以访问和修改内核的状态,包括CPU寄存器、内核栈、全局变量等。执行完处理函数后,CPU会返回到断点处,继续执行原来的内核代码。
kretprobe允许在内核函数返回时插入一个断点,当函数返回时,CPU会先跳转到自定义的处理函数,然后再返回到原来的地址。kretprobe的使用基本上和kprobe是一致的,只是需要将SEC(“kprobe/xxx”)改为SEC(“kretprobe/xxx”)即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 SEC("kprobe/vfs_mkdir" ) int BPF_KPROBE (kprobe_vfs_mkdir) { bpf_printk("kprobe:vfs_mkdir\n" ); return 0 ; }; SEC("kretprobe/vfs_mkdir" ) int BPF_KRETPROBE (kretpobe_mkdir,long retval) { bpf_printk("kretprobe:vfs_mkdir\n" ); return 0 ; };
tracepoint tracepoints是Linux内核中的一种机制,它们是在内核源代码中预定义的钩子点,用于插入用于跟踪和调试的代码。tracepoints在内核中的特定位置被硬编码,每个tracepoint都有一个唯一的名称和一组相关的参数。tracepoints和kprobes/kretprobes都是Linux内核中用于动态跟踪的机制,但它们在使用和性能方面有一些关键的区别。以下是tracepoints的优缺点:
优点:
稳定性:tracepoints是在内核源代码中预定义的,提供了稳定的ABI。即使内核版本升级,tracepoint的名称和参数也不会改变,这使得开发者可以编写依赖于特定tracepoint的代码,而不用担心在未来的内核版本中这些tracepoint会改变。
性能:tracepoints对性能的影响非常小。只有当tracepoint被激活,并且有一个或多个探针附加到它时,才会消耗CPU时间,这使得tracepoints非常适合在生产环境中使用。
缺点:
可用性:tracepoints的数量和覆盖范围有限。并非所有的内核函数都有对应的tracepoint,这限制了可以监控的事件。
1 2 3 4 5 6 SEC("tracepoint/sock/inet_sock_set_state" ) int handle_ssh_conn (struct trace_event_raw_inet_sock_set_state *ctx) { bpf_printk("tracepoint:sock:inet_sock_set_state\n" ); return 0 ; }
socket socket就是和网络包相关的事件,常见的网络包处理函数有sock_filter和sockops。eBPF所有可以处理的事件类型都在bpf.h文件中定义。其中和socket相关的事件有:
BPF_PROG_TYPE_SOCKET_FILTER:用于套接字过滤器,可过滤套接字接收的数据包。
BPF_PROG_TYPE_SOCK_OPS:用于套接字操作,跟踪TCP连接状态变化(如连接建立、重传、拥塞控制)。
BPF_PROG_TYPE_SK_SKB:用于套接字级别的数据包处理,配合sockmap实现套接字之间的数据包转发。
BPF_PROG_TYPE_SK_MSG:用于套接字消息处理,在sendmsg/recvmsg系统调用层面执行。
BPF_PROG_TYPE_SK_LOOKUP:用于套接字查找,在数据包到达时自定义选择目标套接字。
BPF_PROG_TYPE_SK_REUSEPORT:用于SO_REUSEPORT套接字选择,在多个监听套接字之间选择接收连接的目标。
1 2 3 4 5 6 SEC("socket/sock_filter" ) int socket_sock_filter (void *ctx) { bpf_printk("socket:sock_filter\n" ); return 0 ; };
tc TC的全称是Traffic Control,即流量控制。通过TC可以对网络流量进行控制,例如限速、限流、负载均衡等。
从内核4.1开始,TC支持加载eBPF程序到子系统的Hook点,并且在之后的内核4.4中引入了direct-action模式,Cilium、Calico等网络插件大量使用TC Hook来控制网络包的转发。子系统包括qdisc、class、classifier(filter)、action等概念,eBPF程序可以作为classifier被挂载。想较于其它类型的事件,需要额外引入uapi/linux/pkt_cls.h文件,pkt_cls.h头文件提供了一组用于数据包分类的常量、数据结构和函数原型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 出流量 SEC("classifier/egress" ) int egress_cls_func (struct __sk_buff *skb) { bpf_printk("classifier:egress\n" ); return TC_ACT_OK; }; # 进流量 SEC("classifier/ingress" ) int ingress_cls_func (struct __sk_buff *skb) { bpf_printk("classifier:ingress\n" ); return TC_ACT_OK; };
xdp XDP的全称是eXpress Data Path,即即快速数据路径。XDP机制通过将eBPF程序附加到网络设备的接收路径上来提高网络性能和降低延迟。具体而言,XDP程序会在数据包进入网络设备的接收队列之前执行,这样可以在内核中进行快速的数据包过滤和处理,而无需将数据包传递给用户空间。
TC和XDP是Linux网络中两种不同的数据包处理机制,它们的区别如下:
位置不同。TC位于Linux网络协议栈的较高层,主要用于在网络设备的出入口处对数据包进行分类、调度和限速等操作;XDP位于网络设备驱动程序的接收路径上,用于快速处理数据包并决定是否将其传递给协议栈。
执行时机不同。TC在数据包进入或离开网络设备时执行,通常在内核空间中进行;XDP在数据包进入网络设备驱动程序的接收路径时执行,可以在内核空间中或用户空间中执行。
处理能力不同。TC提供了更复杂的流量控制和分类策略,可以实现各种QoS功能,它可以对数据包进行过滤、限速、排队等操作;XDP主要用于快速的数据包过滤和处理,以降低延迟和提高性能。
1 2 3 4 5 6 SEC("xdp/ingress" ) int egress_cls_func (struct __sk_buff *skb) { bpf_printk("xdp:ingress\n" ); return XDP_PASS; };
uprobe uprobe是User Probe的缩写,它利用了Linux内核中的ftrace(function trace)框架来实现。通过uprobe,可以在用户空间程序的指定函数入口或出口处插入探测点,当该函数被调用或返回时,可以触发事先定义的处理逻辑。相较于kprobe是用于监控内核态的程序,uprobe则是用于监控用户态的程序。
1 2 3 4 5 6 SEC("uprobe/readline" ) int uprobe_readline (void *ctx) { bpf_printk("uprobe:readline\n" ); return 0 ; };
程序插桩 内核插桩点 以监控和诊断领域为例,跟踪类eBPF程序的事件源包含内核函数(kprobe),内核跟踪点(tracepoint)和性能事件(perf_event)三类。
如何获取内核函数/内核跟踪点/性能事件
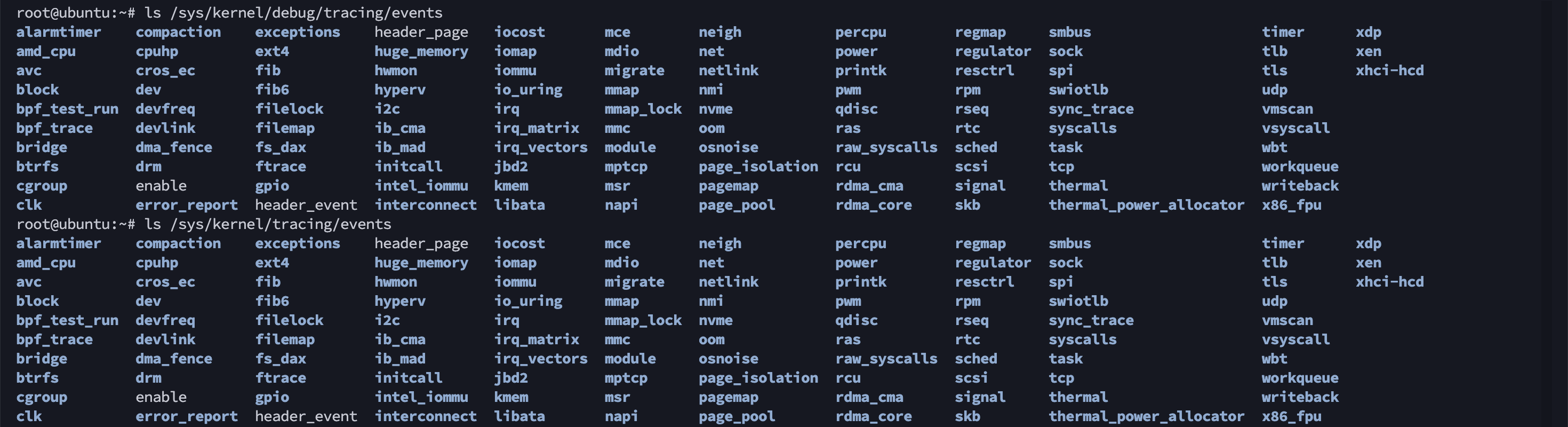
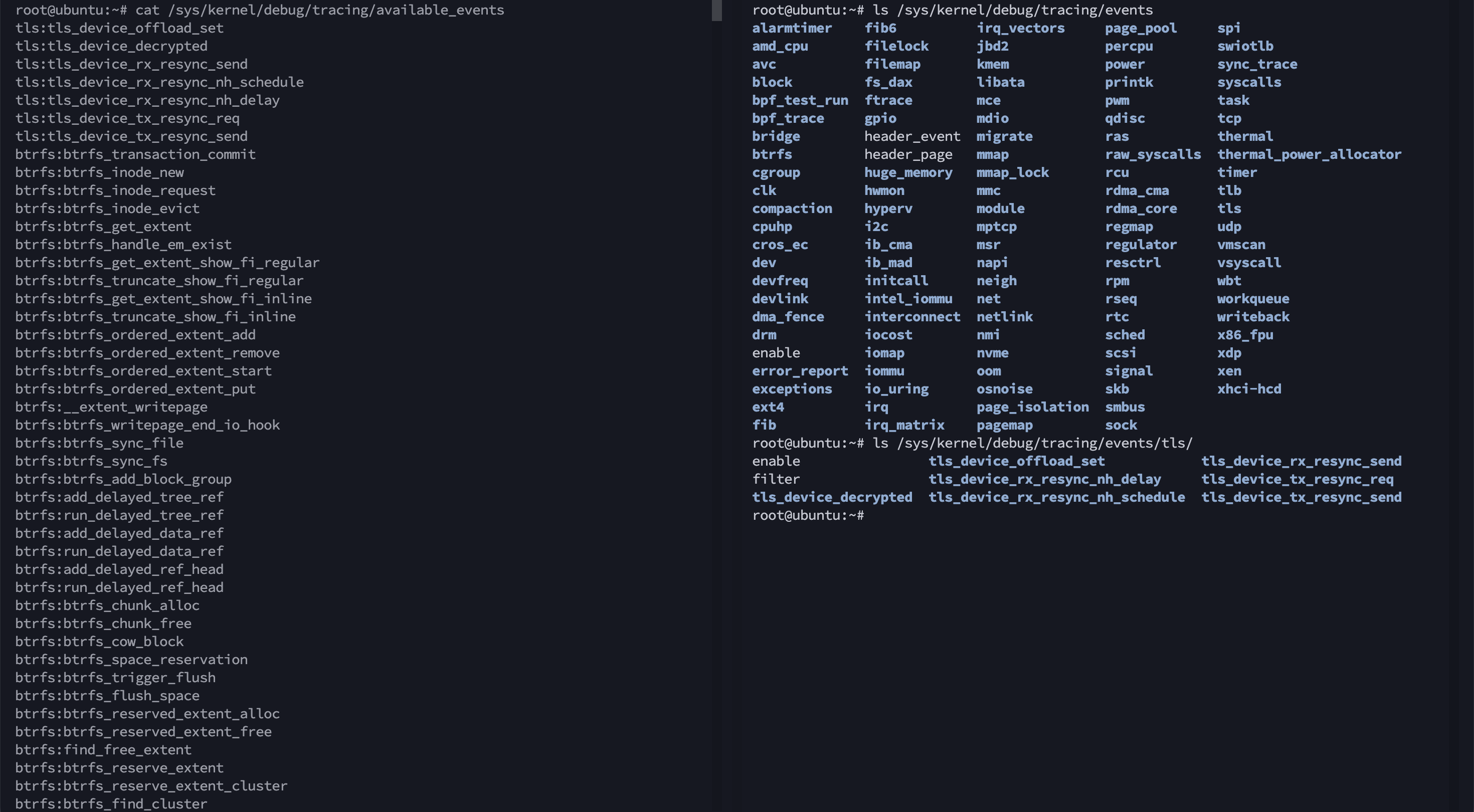
通过Linux内核的跟踪事件调试信息/sys/kernel/debug/tracing/events来获取内核函数、内核跟踪点,在/sys/kernel/debug/tracing/available_events文件里可以看到系统中所有可用跟踪点的汇总结果。
对于基于BTF的eBPF跟踪程序(如fentry/fexit),通常只有包含BTF信息的内核函数才可以进行动态跟踪;而传统kprobe可以探测/proc/kallsyms中可见的绝大多数符号,但可能因编译优化(内联、静态)或运行时状态而受限。可以通过/sys/kernel/tracing/available_filter_functions或/proc/kallsyms查看各内核函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 root@ubuntu:~# grep tcp_sendmsg /proc/kallsyms ffffffff89bcd9c0 T tcp_sendmsg ffffffff89cf5790 t mptcp_sendmsg root@ubuntu:~# perf probe --add tcp_sendmsg Added new event: probe:tcp_sendmsg (on tcp_sendmsg) You can now use it in all perf tools, such as: perf record -e probe:tcp_sendmsg -aR sleep 1 root@ubuntu:~# bpftool btf dump file /sys/kernel/btf/vmlinux | grep tcp_sendmsg [41519] STRUCT 'mptcp_sendmsg_info' size=20 vlen=6 [71757] FUNC 'espintcp_sendmsg' type_id=71756 linkage=static [90594] FUNC 'mptcp_sendmsg' type_id=90593 linkage=static [90596] FUNC 'mptcp_sendmsg_frag' type_id=90595 linkage=static [111577] FUNC 'tcp_sendmsg' type_id=71756 linkage=static [111578] FUNC 'tcp_sendmsg_locked' type_id=71756 linkage=static
使用bpftrace来获取内核函数、内核跟踪点,使用perf list获取性能事件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 bpftrace -l | wc -l bpftrace -l 'tracepoint:syscalls:*' | wc -l bpftrace -l 'tracepoint:syscalls:*' | grep -E "(open|read|write|close)" bpftrace -l 'tracepoint:syscalls:*' | grep -E "(socket|bind|connect|send|recv|accept)" bpftrace -l 'tracepoint:syscalls:*' | grep -E "(fork|clone|exec|exit)" bpftrace -l 'tracepoint:syscalls:*' | grep -E "(access|chmod|chown|stat)" bpftrace -l 'tracepoint:syscalls:*' | grep -E "m(map|protect|unlock|advise)" perf list tracepoint
如何查看内核函数/跟踪点的参数和数据结构
使用调试信息获取。以sock的inet_sock_set_state为例,查看调试信息下的format文件。注意,format列出的字段中,前8个字节对应的字段普通的ebpf程序都不能直接访问(部分bpf helpers辅助函数可以访问),其他的字段一般都可以访问,具体以print fmt中引用的字段为准。对于kprobe,是无法通过上面方式获取参数的,可从内核代码找对应的内核函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 root@ubuntu:~# cat /sys/kernel/debug/tracing/events/sock/inet_sock_set_state/format name: inet_sock_set_state ID: 1477 format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:const void * skaddr; offset:8; size:8; signed:0; field:int oldstate; offset:16; size:4; signed:1; field:int newstate; offset:20; size:4; signed:1; field:__u16 sport; offset:24; size:2; signed:0; field:__u16 dport; offset:26; size:2; signed:0; field:__u16 family; offset:28; size:2; signed:0; field:__u16 protocol; offset:30; size:2; signed:0; field:__u8 saddr[4]; offset:32; size:4; signed:0; field:__u8 daddr[4]; offset:36; size:4; signed:0; field:__u8 saddr_v6[16]; offset:40; size:16; signed:0; field:__u8 daddr_v6[16]; offset:56; size:16; signed:0; print fmt : "family=%s protocol=%s sport=%hu dport=%hu saddr=%pI4 daddr=%pI4 saddrv6=%pI6c daddrv6=%pI6c oldstate=%s newstate=%s" , __print_symbolic(REC->family, { 2, "AF_INET" }, { 10, "AF_INET6" }), __print_symbolic(REC->protocol, { 6, "IPPROTO_TCP" }, { 33, "IPPROTO_DCCP" }, { 132, "IPPROTO_SCTP" }, { 262, "IPPROTO_MPTCP" }), REC->sport, REC->dport, REC->saddr, REC->daddr, REC->saddr_v6, REC->daddr_v6, __print_symbolic(REC->oldstate, { 1, "TCP_ESTABLISHED" }, { 2, "TCP_SYN_SENT" }, { 3, "TCP_SYN_RECV" }, { 4, "TCP_FIN_WAIT1" }, { 5, "TCP_FIN_WAIT2" }, { 6, "TCP_TIME_WAIT" }, { 7, "TCP_CLOSE" }, { 8, "TCP_CLOSE_WAIT" }, { 9, "TCP_LAST_ACK" }, { 10, "TCP_LISTEN" }, { 11, "TCP_CLOSING" }, { 12, "TCP_NEW_SYN_RECV" }), __print_symbolic(REC->newstate, { 1, "TCP_ESTABLISHED" }, { 2, "TCP_SYN_SENT" }, { 3, "TCP_SYN_RECV" }, { 4, "TCP_FIN_WAIT1" }, { 5, "TCP_FIN_WAIT2" }, { 6, "TCP_TIME_WAIT" }, { 7, "TCP_CLOSE" }, { 8, "TCP_CLOSE_WAIT" }, { 9, "TCP_LAST_ACK" }, { 10, "TCP_LISTEN" }, { 11, "TCP_CLOSING" }, { 12, "TCP_NEW_SYN_RECV" })
使用bpftrace获取。
1 2 3 4 5 6 7 8 9 10 11 12 13 root@ubuntu:~# bpftrace -lv tracepoint:sock:inet_sock_set_state tracepoint:sock:inet_sock_set_state const void * skaddr int oldstate int newstate __u16 sport __u16 dport __u16 family __u16 protocol __u8 saddr[4] __u8 daddr[4] __u8 saddr_v6[16] __u8 daddr_v6[16]
应用插桩点
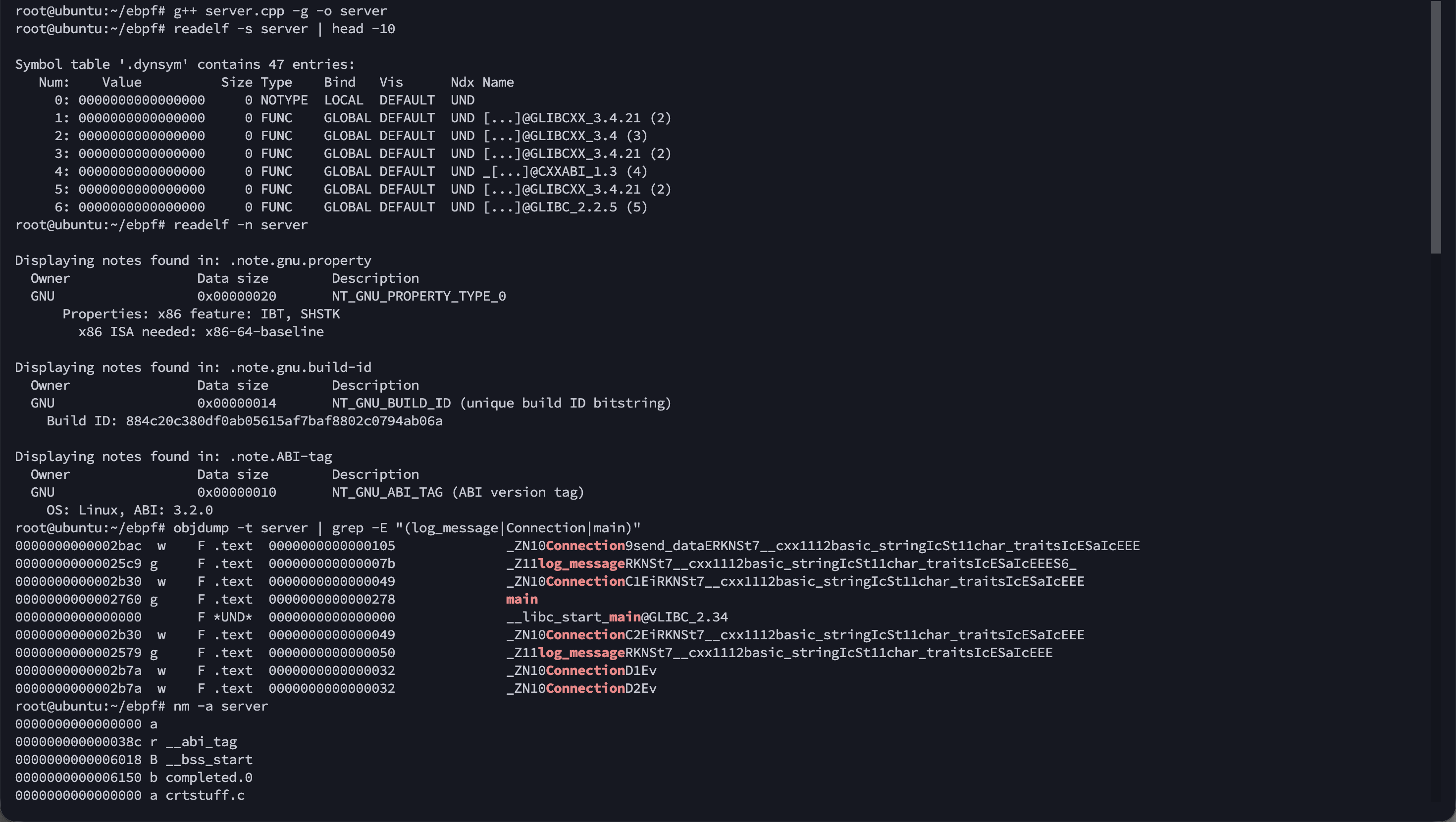
使用readelf、objdump、nm查询。静态编译语言通过-g编译选项保留调试信息,应用程序二进制会包含DWARF(Debugging With Attributed Record Format),有了调试信息,可以通过readelf、objdump、nm等工具来查询可用于跟踪的函数、变量等符号列表。
1 2 3 4 5 6 7 8 9 readelf -s xxxxxx readelf -n xxxxxx
使用bpftrace查询。
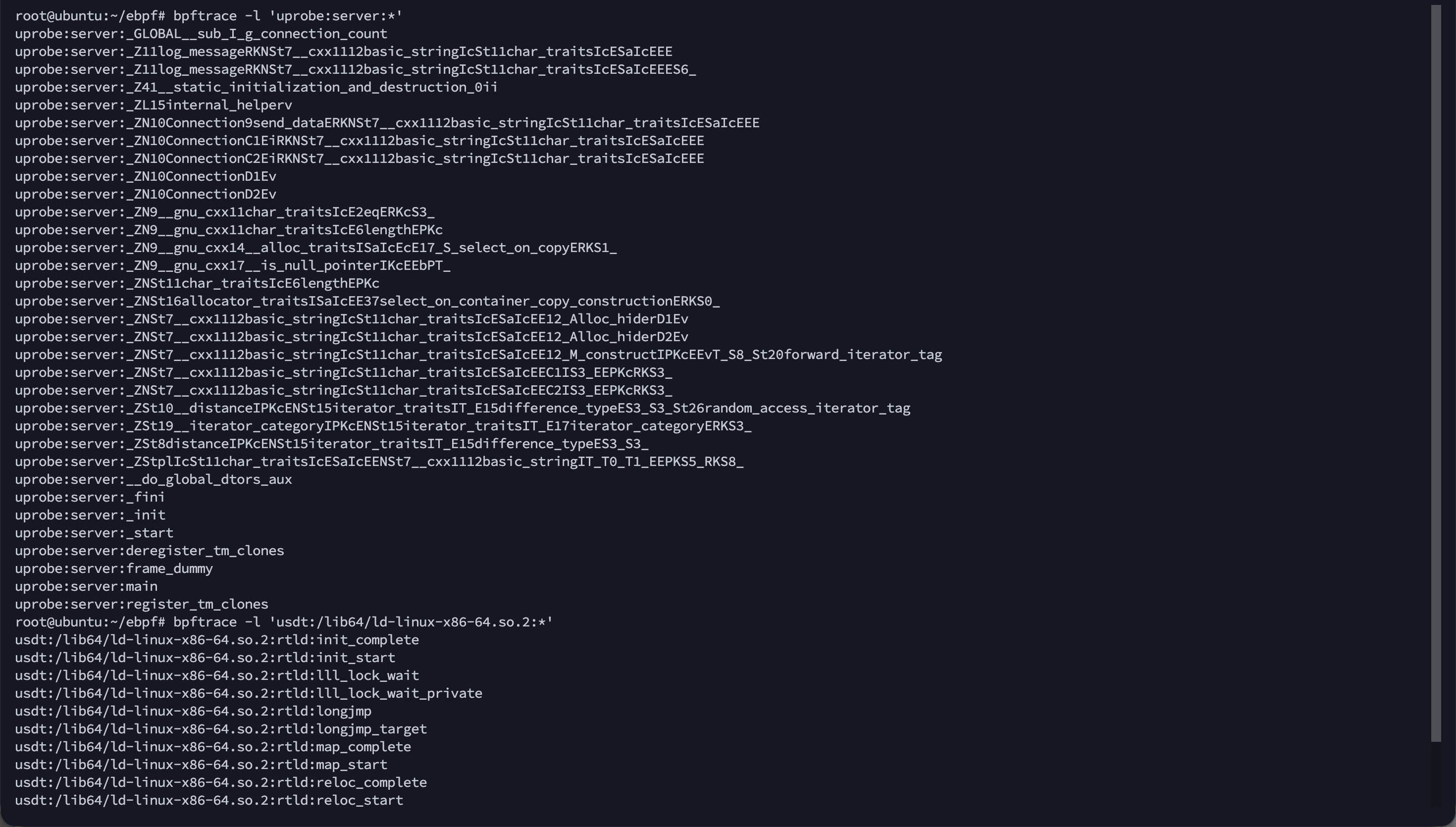
1 2 3 4 5 bpftrace -l 'uprobe:xxxxxx:*' bpftrace -l 'usdt:xxxxxx:*'
环境搭建 由于eBPF是内核技术,因此需要具备较新版本的Linux内核(推荐Ubuntu24.04),以支持eBPF功能。以ebpf-go框架为例,安装如下依赖与相关包:
1 2 3 4 5 6 7 sudo apt-get install -y make clang llvm libelf-dev libbpf-dev bpfcc-tools libbpfcc-dev linux-tools-$(uname -r) linux-headers-$(uname -r)go env -w GOPROXY=https://goproxy.cn,direct go install github.com/cilium/ebpf/cmd/bpf2go@latest go install github.com/aya-rs/bpf-linker@latest echo 'export PATH=$PATH:$(go env GOPATH)/bin' >> ~/.bashrcsource ~/.bashrc
或者可以搭建一个Docker环境来进行代码的编写和编译。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 FROM --platform=linux/amd64 ubuntu:24.04 ENV DEBIAN_FRONTEND=noninteractiveENV CLANG_VERSION=18 ENV SSH_USER=rootENV SSH_PASSWORD=rootRUN set -eux; \ sed -i 's|http://archive.ubuntu.com/ubuntu|https://mirrors.aliyun.com/ubuntu|g' /etc/apt/sources.list && \ sed -i 's|http://security.ubuntu.com/ubuntu|https://mirrors.aliyun.com/ubuntu|g' /etc/apt/sources.list && \ apt-get update && \ apt-get install -y --no-install-recommends \ ca-certificates build-essential git make cmake pkg-config \ curl wget vim openssh-server sudo \ clang-${CLANG_VERSION} \ lld-${CLANG_VERSION} \ llvm-${CLANG_VERSION} \ llvm-${CLANG_VERSION} -dev \ libclang-${CLANG_VERSION} -dev \ libbpf-dev \ libelf-dev \ zlib1g-dev \ libssl-dev \ linux-headers-generic \ libc6-dev-amd64-cross \ gcc-x86-64-linux-gnu \ linux-tools-generic \ libncurses-dev \ libcap-dev \ libbfd-dev \ trace-cmd tcpdump strace \ iproute2 iputils-ping net-tools ethtool \ python3 python3-pip python3-dev \ python3-setuptools python3-wheel \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* RUN update-alternatives --install /usr/bin/clang clang /usr/bin/clang-${CLANG_VERSION} 100 \ && update-alternatives --install /usr/bin/clang++ clang++ /usr/bin/clang++-${CLANG_VERSION} 100 \ && update-alternatives --install /usr/bin/llc llc /usr/bin/llc-${CLANG_VERSION} 100 \ && update-alternatives --install /usr/bin/llvm-strip llvm-strip /usr/bin/llvm-strip-${CLANG_VERSION} 100 \ && update-alternatives --install /usr/bin/llvm-objdump llvm-objdump /usr/bin/llvm-objdump-${CLANG_VERSION} 100 RUN set -eux; \ git clone --recurse-submodules --depth=1 https://github.com/libbpf/bpftool.git /tmp/bpftool && \ cd /tmp/bpftool/src && \ make -j$(nproc ) && \ make install && \ bpftool version && \ rm -rf /tmp/bpftool ENV GOPATH=/root/goENV PATH=$PATH:/usr/local/go/bin:$GOPATH/binRUN set -eux; \ arch ="$(dpkg --print-architecture) " ; \ wget -q "https://go.dev/dl/go1.24.0.linux-${arch} .tar.gz" -O /tmp/go.tar.gz && \ tar -C /usr/local -xzf /tmp/go.tar.gz && \ rm /tmp/go.tar.gz && \ go version RUN set -eux; \ go env -w GOPROXY=https://goproxy.cn,direct && \ go env -w GOSUMDB=sum.golang.google.cn && \ go install github.com/cilium/ebpf/cmd/bpf2go@latest && \ which bpf2go ENV CARGO_HOME=/root/.cargoENV RUSTUP_HOME=/root/.rustupENV PATH=$PATH:$CARGO_HOME/binRUN set -eux; \ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y --profile minimal --default-toolchain stable && \ . $CARGO_HOME /env && \ rustup toolchain install nightly && \ rustup component add rust-src --toolchain nightly && \ rustup component add rustfmt clippy && \ cargo install cargo-generate RUN set -eux; \ cat >> /root/.bashrc <<'EOF' export GOPATH=/root/go export CARGO_HOME=/root/.cargo export RUSTUP_HOME=/root/.rustup export PATH=/usr/local/go/bin:$GOPATH/bin:$CARGO_HOME/bin:$PATH EOF RUN set -eux; \ mkdir -p /var/run/sshd && \ echo "root:${SSH_PASSWORD} " | chpasswd && \ mkdir -p /root/.ssh && \ chmod 700 /root/.ssh && \ sed -i 's/^#\?PasswordAuthentication.*/PasswordAuthentication yes/' /etc/ssh/sshd_config && \ sed -i 's/^#\?PermitRootLogin.*/PermitRootLogin yes/' /etc/ssh/sshd_config && \ sed -i 's/^#\?UsePAM.*/UsePAM no/' /etc/ssh/sshd_config && \ ssh-keygen -A WORKDIR /workspace EXPOSE 22 CMD ["/usr/sbin/sshd" , "-D" , "-e" ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 version: "3.8" services: ebpf-dev: build: context: . dockerfile: Dockerfile platforms: - linux/amd64 image: ebpf-dev:latest container_name: ebpf-dev hostname: ebpf-dev privileged: false ports: - "2222:22" volumes: - ./workspace:/workspace - ~/.ssh:/root/.ssh:ro deploy: resources: limits: cpus: '4' memory: 8G environment: - GO_ENV=development - GOPROXY=https://goproxy.cn,direct - GOSUMDB=sum.golang.google.cn restart: unless-stopped stdin_open: true tty: true
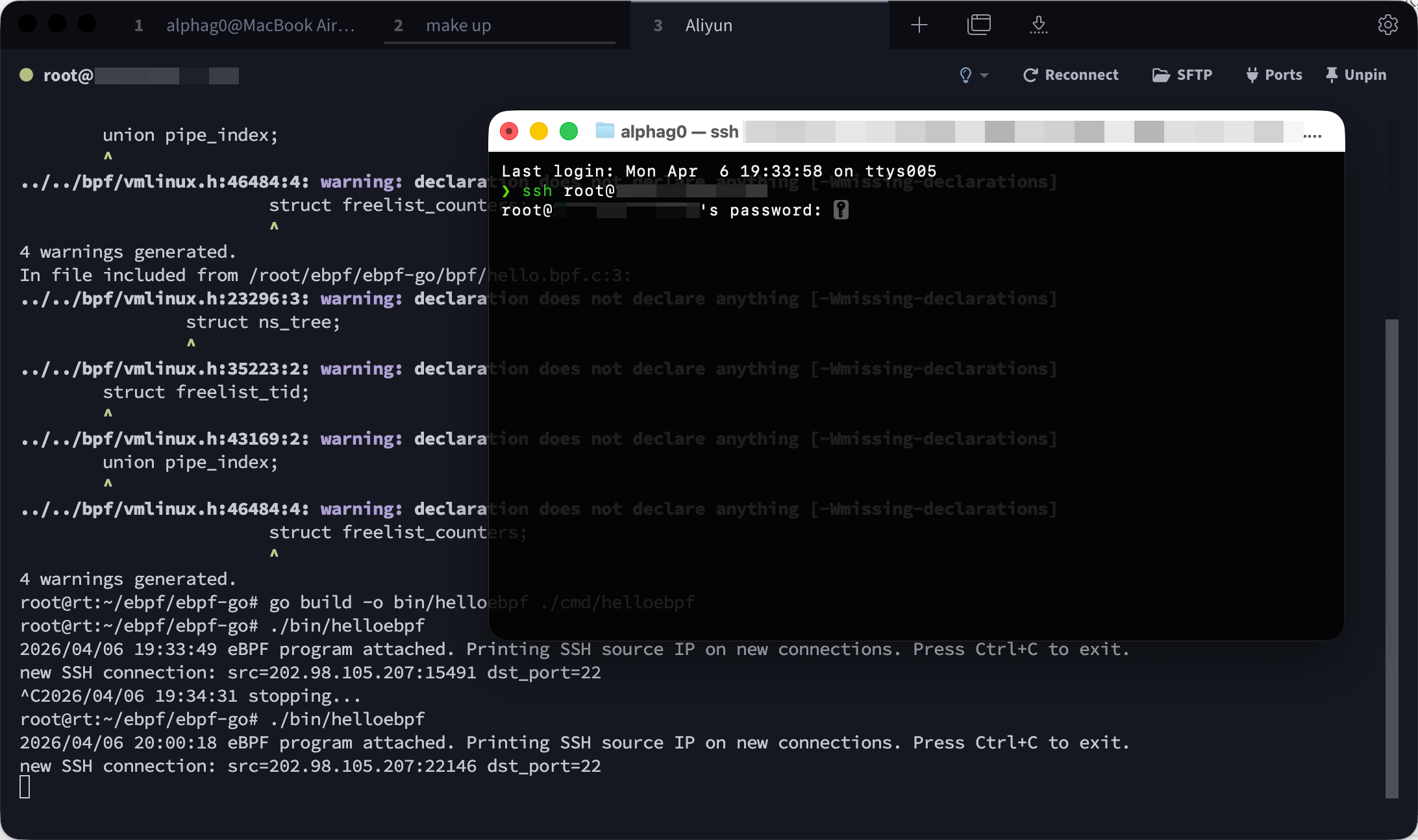
测试代码 先编写一个eBPF程序,并使用bpf2go进行编译,该程序运行在内核态。它挂到sock/inet_sock_set_state tracepoint,筛选IPv4、TCP、状态变为已建立、且本地端口是22的连接,然后把客户端IP、客户端端口和服务端端口写进ring buffer,上报给用户态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #define BPF_NO_GLOBAL_DATA #include "vmlinux.h" #include <bpf/bpf_helpers.h> #include <bpf/bpf_tracing.h> #define AF_INET 2 #define IPPROTO_TCP 6 #define TCP_ESTABLISHED 1 #define SSH_PORT 22 struct event { __u8 src_ip[4 ]; __u16 src_port; __u16 dst_port; }; struct { __uint(type, BPF_MAP_TYPE_RINGBUF); __uint(max_entries, 1 << 24 ); } events SEC (".maps" ) ; SEC("tracepoint/sock/inet_sock_set_state" ) int handle_ssh_conn (struct trace_event_raw_inet_sock_set_state *ctx) { if (ctx->family != AF_INET) { return 0 ; } if (ctx->protocol != IPPROTO_TCP) { return 0 ; } if (ctx->newstate != TCP_ESTABLISHED) { return 0 ; } if (ctx->sport != SSH_PORT) { return 0 ; } struct event *e =sizeof (*e), 0 ); if (e) { e->src_ip[0 ] = ctx->daddr[0 ]; e->src_ip[1 ] = ctx->daddr[1 ]; e->src_ip[2 ] = ctx->daddr[2 ]; e->src_ip[3 ] = ctx->daddr[3 ]; e->src_port = ctx->dport; e->dst_port = ctx->sport; bpf_ringbuf_submit(e, 0 ); } return 0 ; } char LICENSE[] SEC("license" ) = "Dual BSD/GPL" ;
接着编写用户态程序,负责加载eBPF对象、把程序挂到tracepoint、打开ring buffer读事件,并把读到的源IP打印出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 package mainimport ( "bytes" "context" "encoding/binary" "errors" "fmt" "log" "net" "os/signal" "syscall" "github.com/cilium/ebpf/link" "github.com/cilium/ebpf/ringbuf" "github.com/cilium/ebpf/rlimit" ) type event struct { SrcIP [4 ]byte SrcPort uint16 DstPort uint16 } func main () ctx, stop := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM) defer stop() if err := rlimit.RemoveMemlock(); err != nil { log.Fatalf("remove memlock limit failed: %v" , err) } var objs helloObjects if err := loadHelloObjects(&objs, nil ); err != nil { log.Fatalf("load eBPF objects failed: %v" , err) } defer objs.Close() tp, err := link.Tracepoint("sock" , "inet_sock_set_state" , objs.HandleSshConn, nil ) if err != nil { log.Fatalf("attach tracepoint failed: %v" , err) } defer tp.Close() rd, err := ringbuf.NewReader(objs.Events) if err != nil { log.Fatalf("open ring buffer failed: %v" , err) } defer rd.Close() go func () <-ctx.Done() _ = rd.Close() }() log.Println("eBPF program attached. Printing SSH source IP on new connections. Press Ctrl+C to exit." ) for { rec, err := rd.Read() if err != nil { if errors.Is(err, ringbuf.ErrClosed) { log.Println("stopping..." ) return } log.Printf("read ring buffer failed: %v" , err) continue } var e event if err := binary.Read(bytes.NewReader(rec.RawSample), binary.LittleEndian, &e); err != nil { log.Printf("decode event failed: %v" , err) continue } srcIP := net.IPv4(e.SrcIP[0 ], e.SrcIP[1 ], e.SrcIP[2 ], e.SrcIP[3 ]) fmt.Printf("new SSH connection: src=%s:%d dst_port=%d\n" , srcIP.String(), e.SrcPort, e.DstPort) } }
参考 eBPF 文档
eBPF 核心技术与实战